designing 'round the deal
CASE STUDY • AI-Tools • chatgpt • lovable • Supabase
About
Goal
After building DineSwipe, a consumer-facing iOS product, I wanted to deliberately shift gears and work on something deeper, more complex, and closer to the kinds of problems I’ve tackled in full-time product design roles. I used some of my free time to design and build DataFox—a web-based platform focused on helping Private Equity teams make better investment decisions by leveraging AI agent technology. The goal was to explore how modern AI tooling could be applied to real, high-stakes, data-heavy workflows, particularly in environments where trust, traceability, and decision quality matter more than surface-level automation.
I led the project end-to-end, defining the product vision and core workflows, authoring the PRD using ChatGPT, and designing and building the UI using Lovable AI. I selectively implemented backend logic using Supabase and GitHub to support realistic data flows, authentication, and persistence.**The goal of this case study was not production scale, but to push the product as far as possible in real terms—building and validating a complex, deal-centric AI workflow with meaningful, working functionality under realistic constraints.

building something worth hunting

From the outset, I was intentional about how far to take the project. DataFox was built to validate the product vision, core workflows, and AI interaction patterns under realistic conditions—not to claim production readiness. I designed the system end-to-end, defined the architecture, stress-tested the AI behavior with representative data, and iterated until the workflows felt coherent and defensible. Beyond that point, deeper validation around scalability, performance, and long-term reliability would require a dedicated engineering team. Recognizing and respecting that boundary was part of the exercise—treating DataFox as a serious product exploration rather than an over-promised MVP.
personas and ownership

DataFox encodes ownership directly into the workflow rather than relying on permissions alone. Managers control deal definition—creating the transaction, selecting companies, and defining which data points matter—while analysts operate within that structure to execute extraction and verification. By separating definition from execution, the system enables clean handoffs, prevents scope drift, and makes responsibility clear at every stage of the deal.
the cost of noise
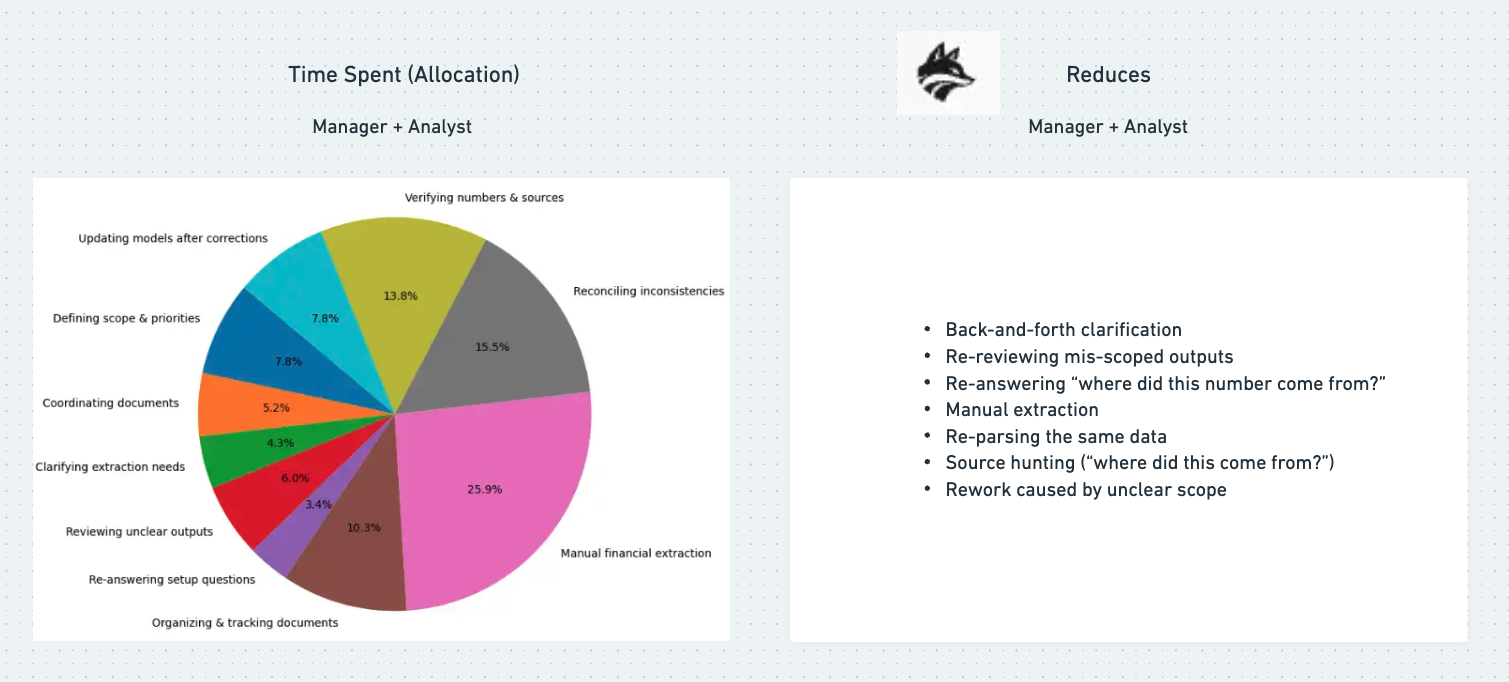
The real problem in private equity isn’t uploading documents—it’s the time lost turning fragmented, disorganized information into trusted, decision-ready signal. Deals accumulate data across multiple companies, formats, and time periods, forcing teams to manually track what’s been reviewed, what’s reliable, and what still needs validation. When extraction, verification, and ownership are bundled into a single workflow, accountability breaks down, rework increases, and confidence in outputs drops. DataFox was designed to solve this by organizing information around the deal, defining scope up front, and ensuring that extracted data is explainable, verifiable, and clearly owned—shortening the path from raw documents to confident investment decisions.
from raw documents to trusted signal
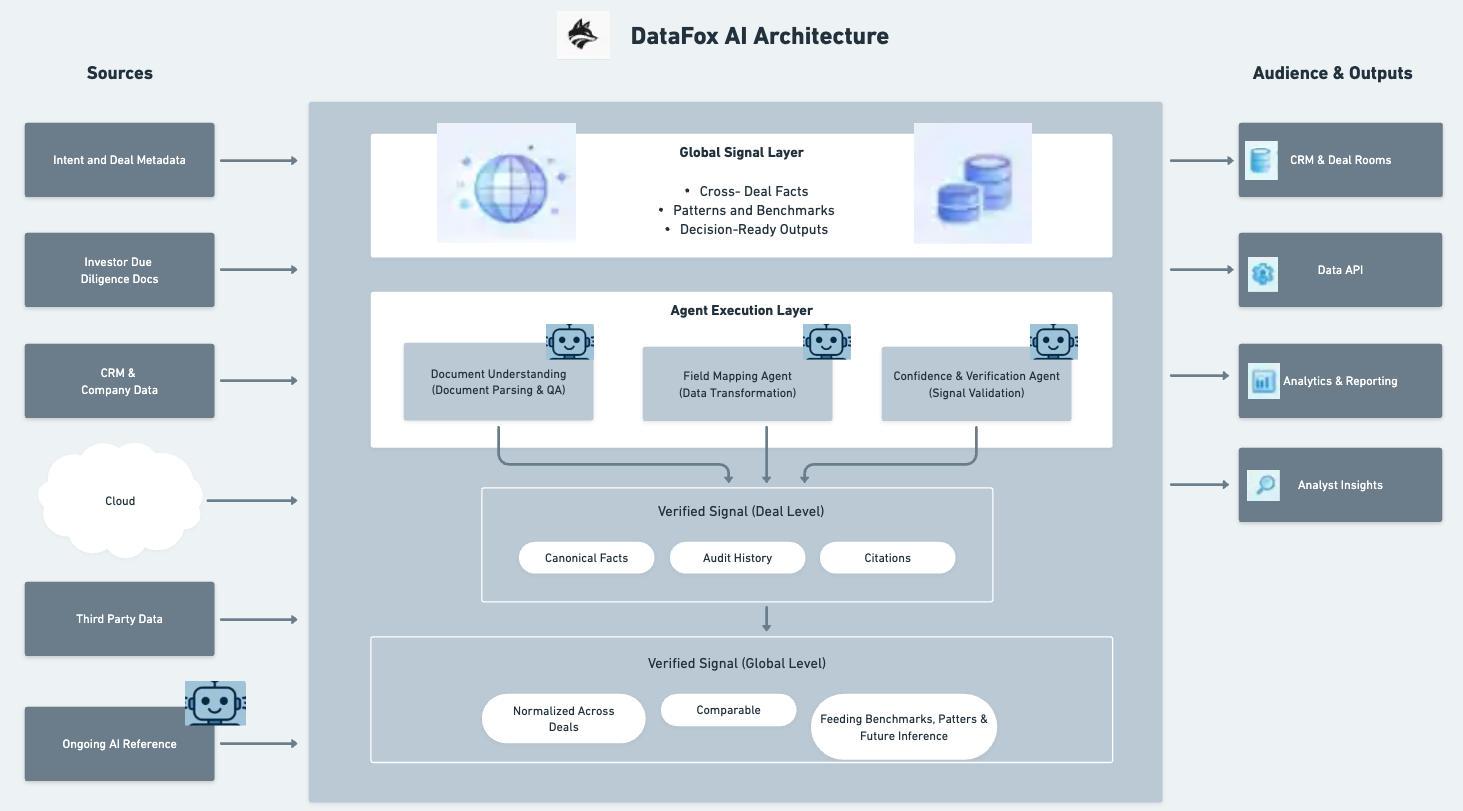
I believed that leveraging a multi-agent AI model was the right approach for this problem, because private equity work depends on understanding an entire deal data room—not isolated documents. By having specialized agents operate in parallel to interpret document structure, map evidence to predefined extraction points, score confidence, and generate rationale—while a separate retrieval agent supports conversational exploration—DataFox aligns AI behavior with how real diligence happens. This separation ensures that only verified, explainable data is promoted into the system’s canonical layer, while exploratory questions remain non-destructive. The result is an AI system intentionally designed for trust, traceability, and scale, rather than raw extraction alone.
rethinking document-first
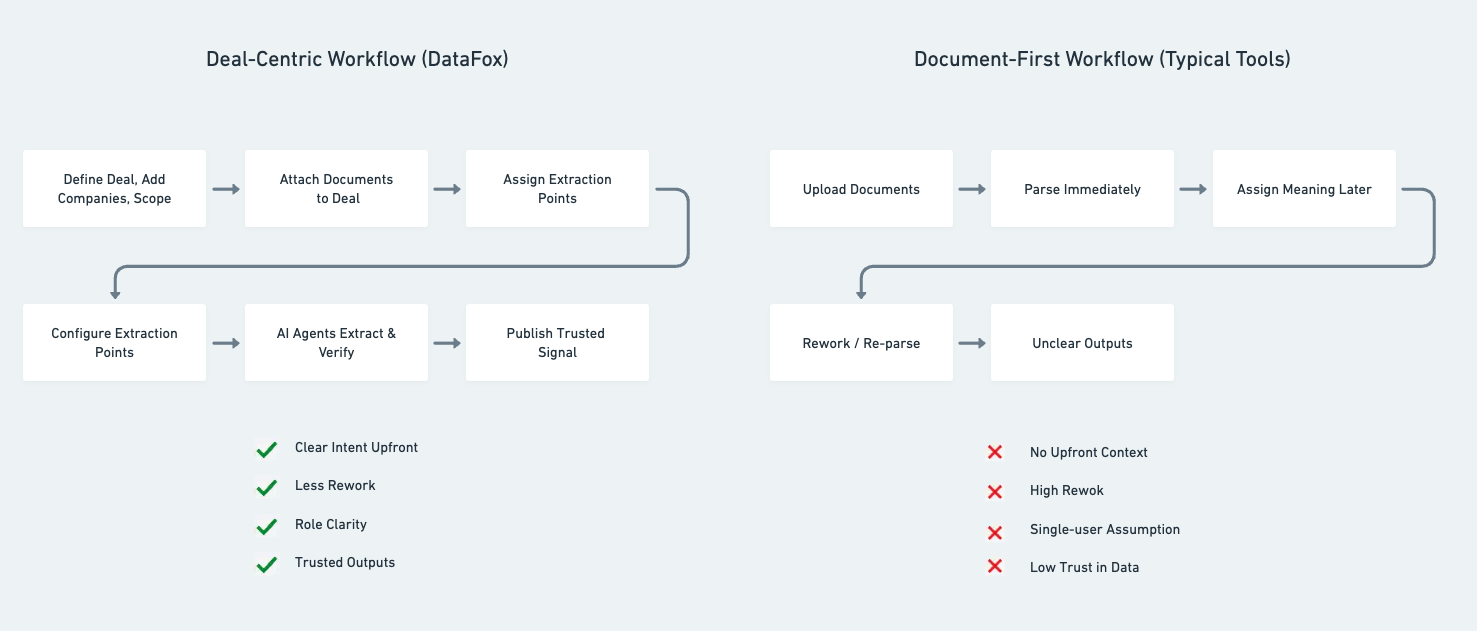
While evaluating the landscape of AI-powered diligence tools, I noticed that most products are fundamentally document-first—optimized for bulk ingestion and extraction, but disconnected from user intent. These workflows push teams into execution before scope, ownership, or success criteria are defined, often producing noisy outputs and fragmented insights that are hard to translate into real investment decisions. I intentionally designed DataFox as a deal-centric product instead, reflecting how private equity teams actually work: starting with the transaction, defining the companies involved, and clarifying which data points matter before any documents are processed. By anchoring the workflow around the deal, every document, field set, and AI-generated insight stays tied to a clear decision context, enabling cleaner handoffs, less noise, and more decision-ready summaries downstream.
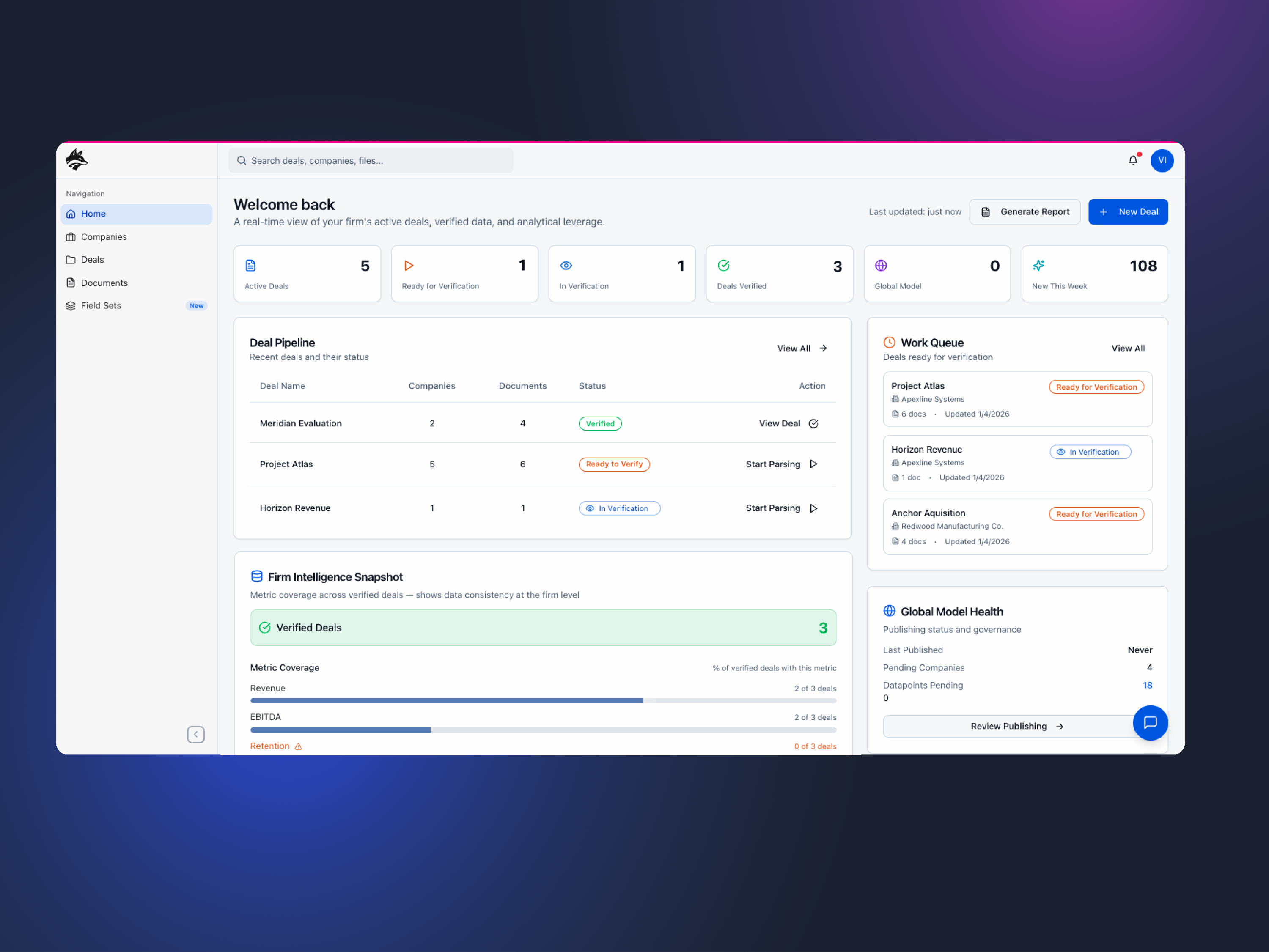
primary Workflow: deal creation
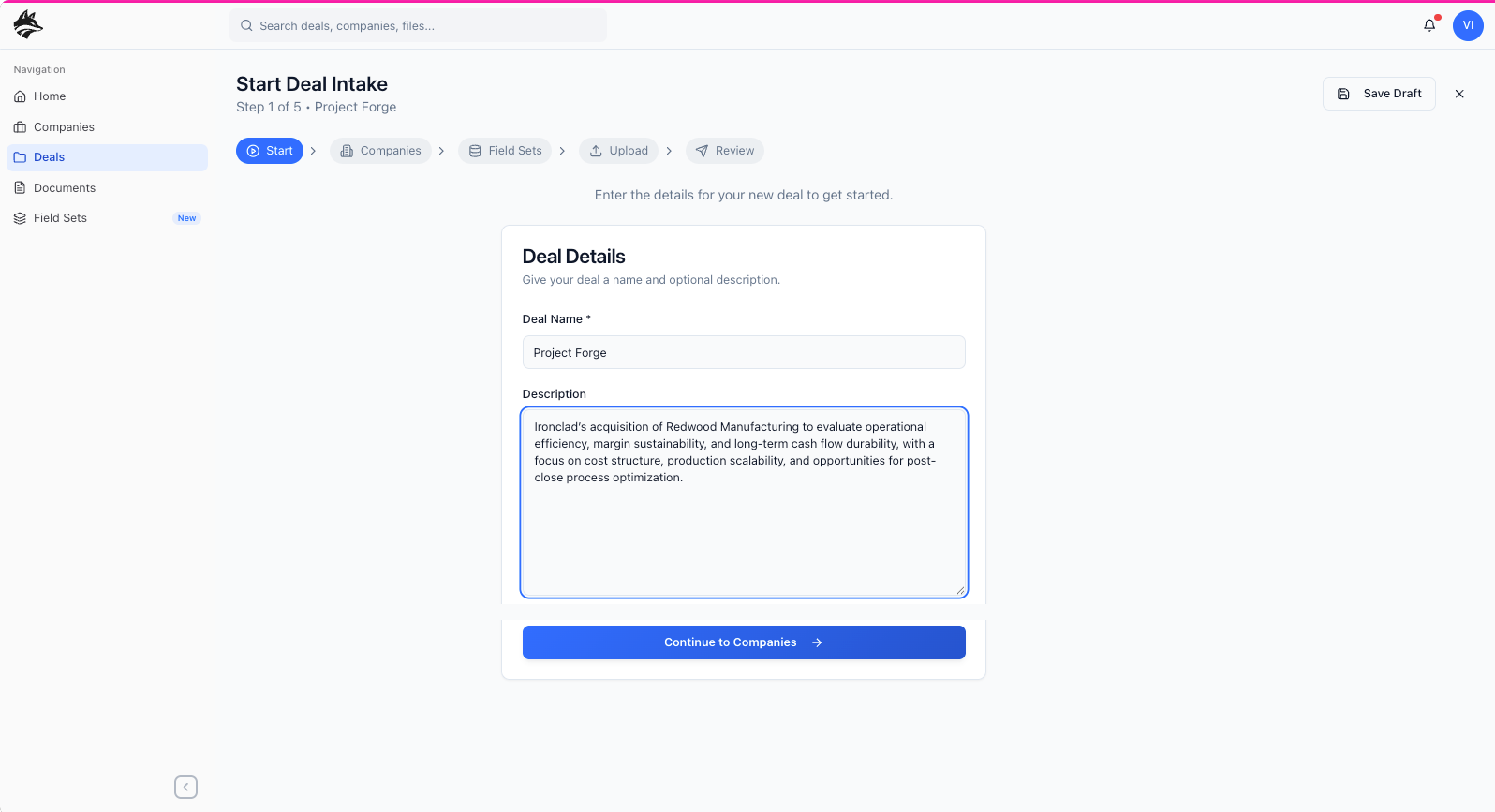
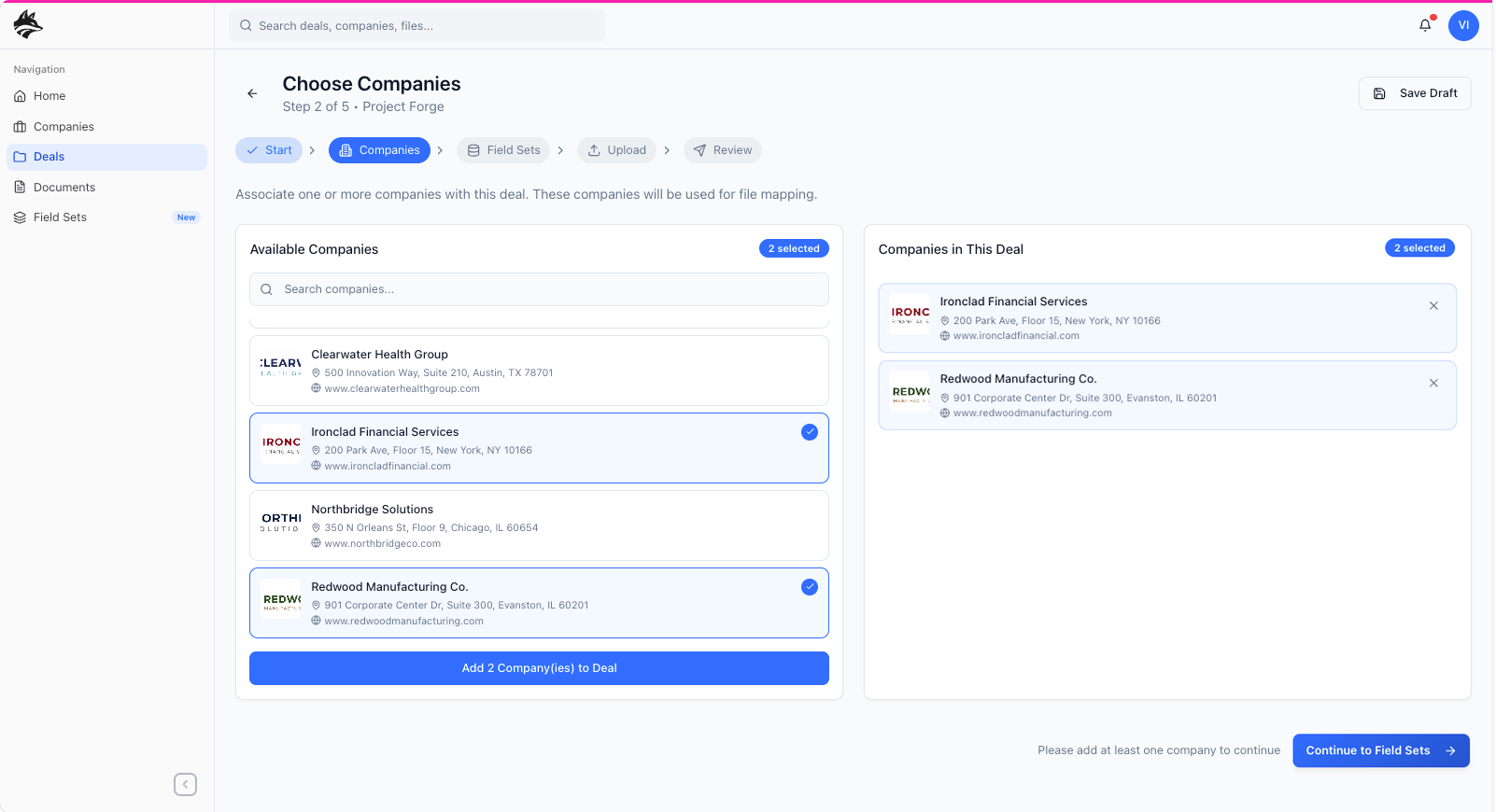
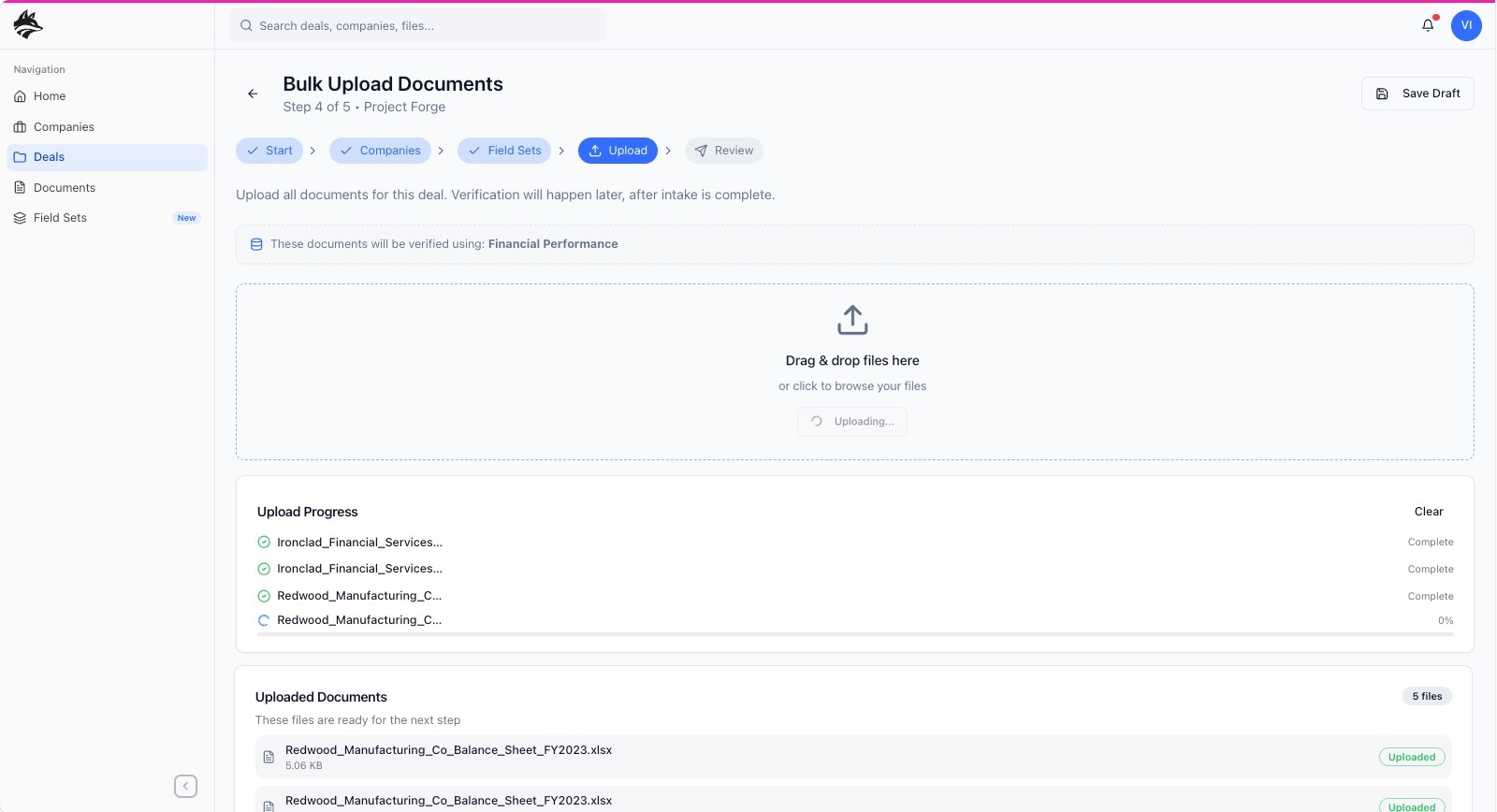
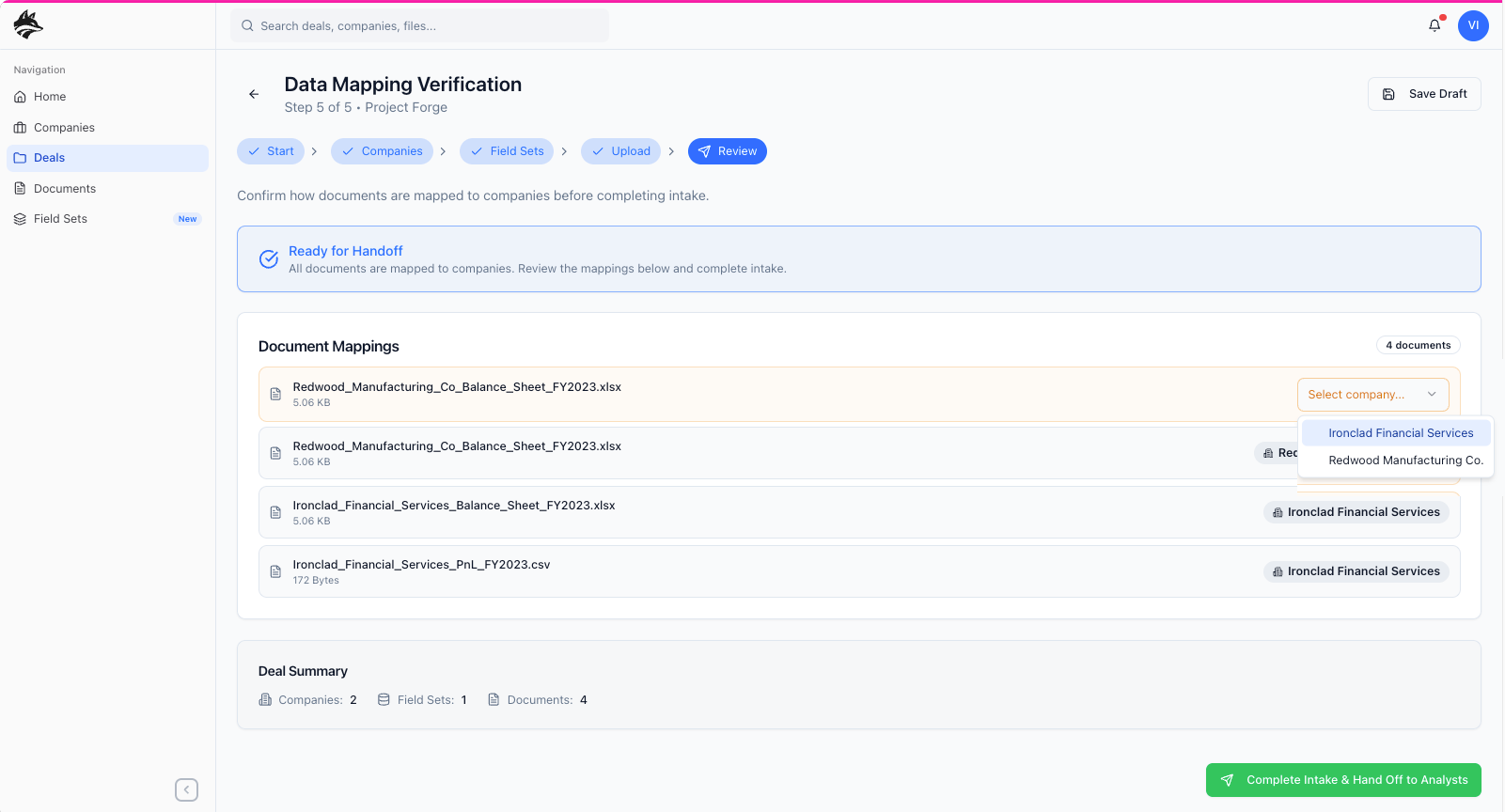
I approached DataFox by first identifying and designing the primary workflow that everything else would depend on: the “Create a Deal” experience. Rather than treating features as isolated modules, I framed the product around how private equity teams actually work, starting from the moment a deal is initiated. This meant designing an intentional flow where a manager defines the deal, adds the companies under evaluation, uploads relevant documents, and explicitly chooses which data points matter for that specific transaction—ensuring that only meaningful, contextual information is extracted and surfaced. Those validated outputs then feed into both the company detail pages and, ultimately, a larger global model that aggregates insights across all deals. By anchoring the product around this workflow—and modeling it after real-world PE processes with a clear handoff from manager to analyst—I established the core user experience, or “meat and potatoes,” of the platform before layering on any secondary features or optimizations.
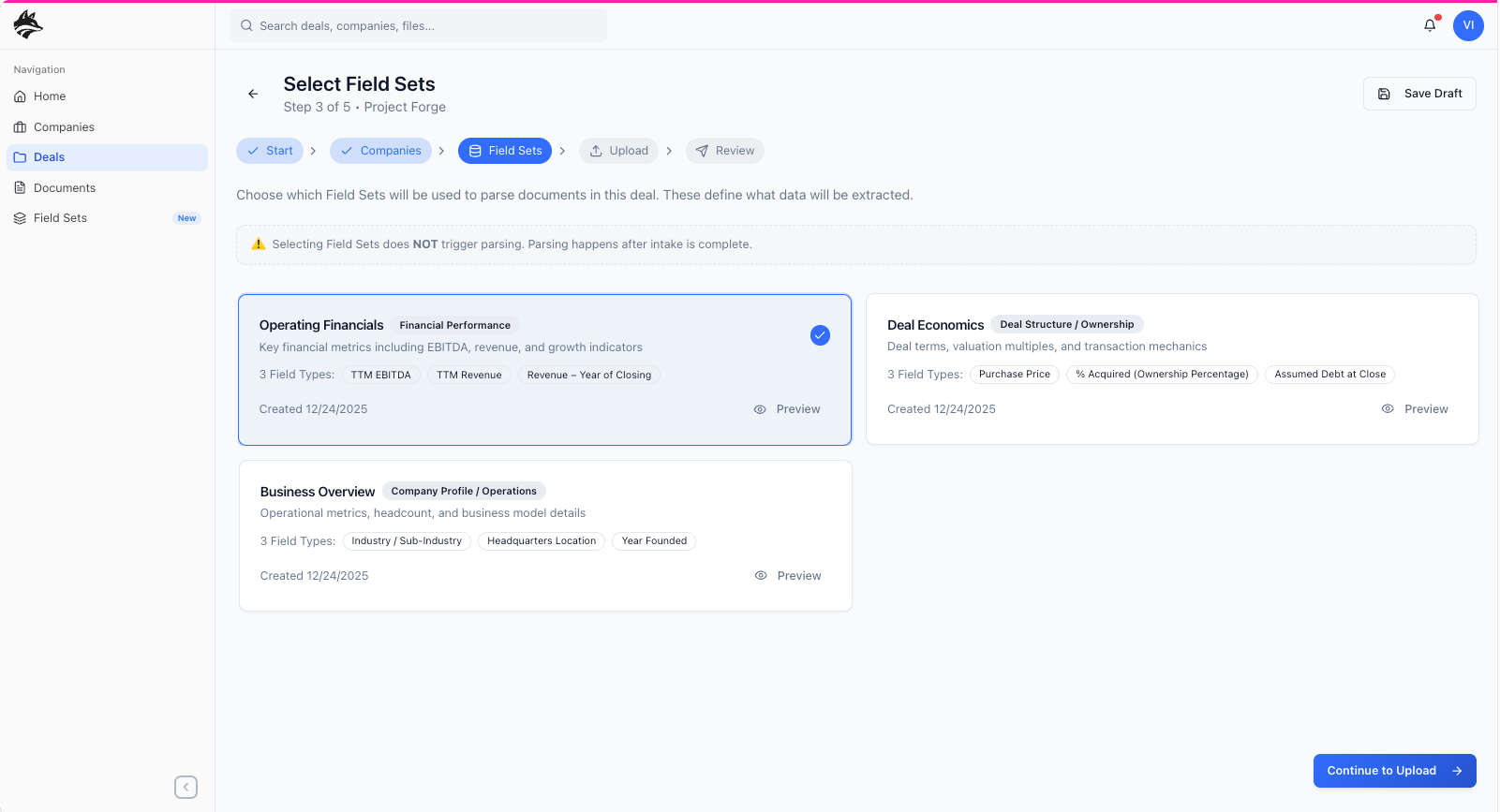
primary workflow deep dive: field sets

Step three of the core workflow centers on Field Sets, where a manager selects the analytical framework that best aligns with the goal of the deal before any documents are uploaded. During onboarding, managers are guided toward commonly used, predefined field sets—such as Financial Performance or Deal Structure—each initialized with sensible default states based on typical diligence needs. What’s shown above is a vertically stacked summary view of a single field set: the top card represents the Field Set itself, defining the overall analytical lens; the second card summarizes an individual Field Type, breaking that lens into a specific data category such as revenue, EBITDA, or ownership; and the third card surfaces the Outputs, the structured data points the system will extract and standardize from source documents. By defining this hierarchy up front—Field Sets → Field Types → Outputs—managers declare intent and scope before execution, ensuring extraction is targeted, predictable, and directly aligned with the decision the deal is meant to support.
primary workflow deep dive: architecture
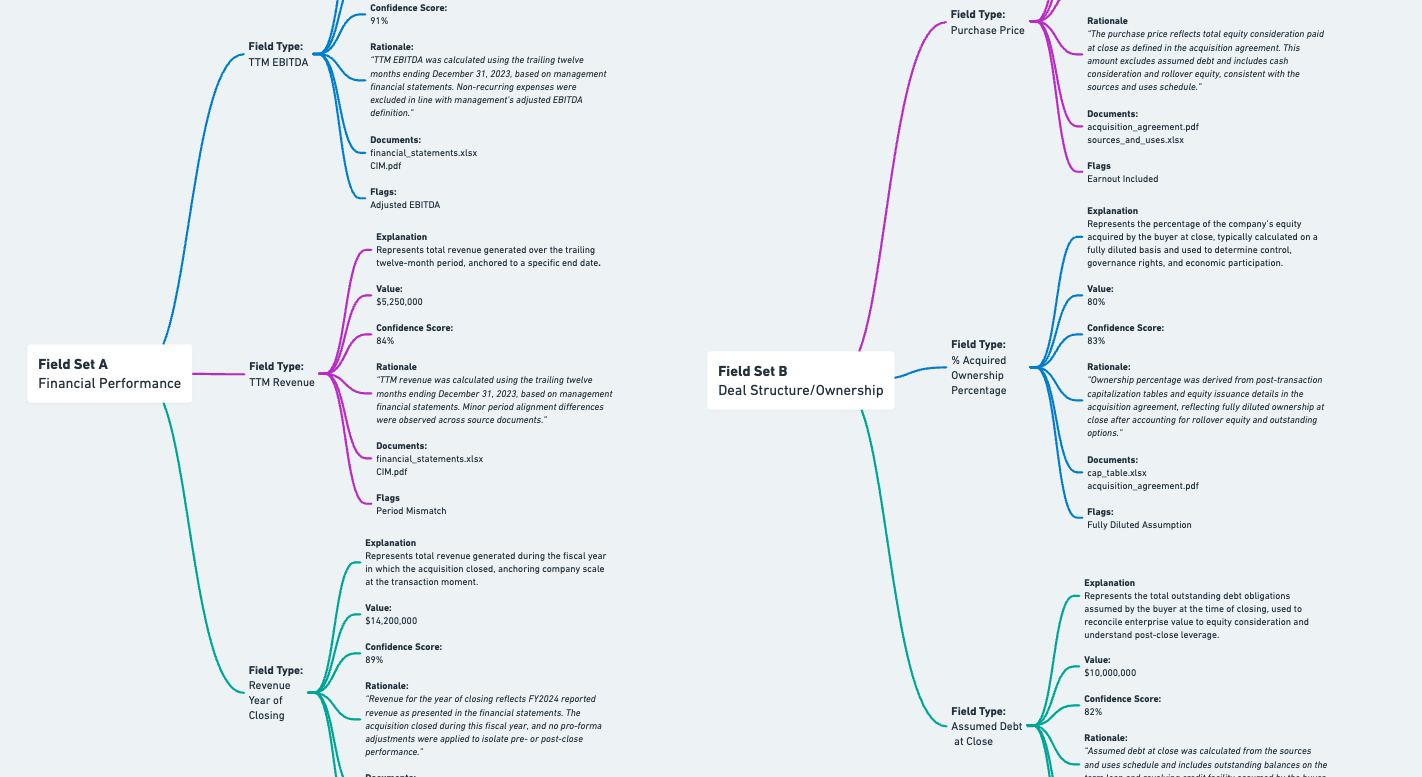
In the example above, a single deal applies two field sets: Financial Performance and Deal Structure / Ownership. The Financial Performance field set breaks down into field types like TTM Revenue, TTM EBITDA, and Revenue Year of Closing, each resolving into structured outputs that include the extracted value, supporting documents, rationale, and confidence. Alongside it, the Deal Structure field set captures how the transaction is constructed—such as purchase price, percentage acquired, and assumed debt at close—using the same output structure. Together, these field sets provide a complete view of both how the business performs and how the deal is being executed, all derived from the same underlying documents.
secondary workflow: analyst verification
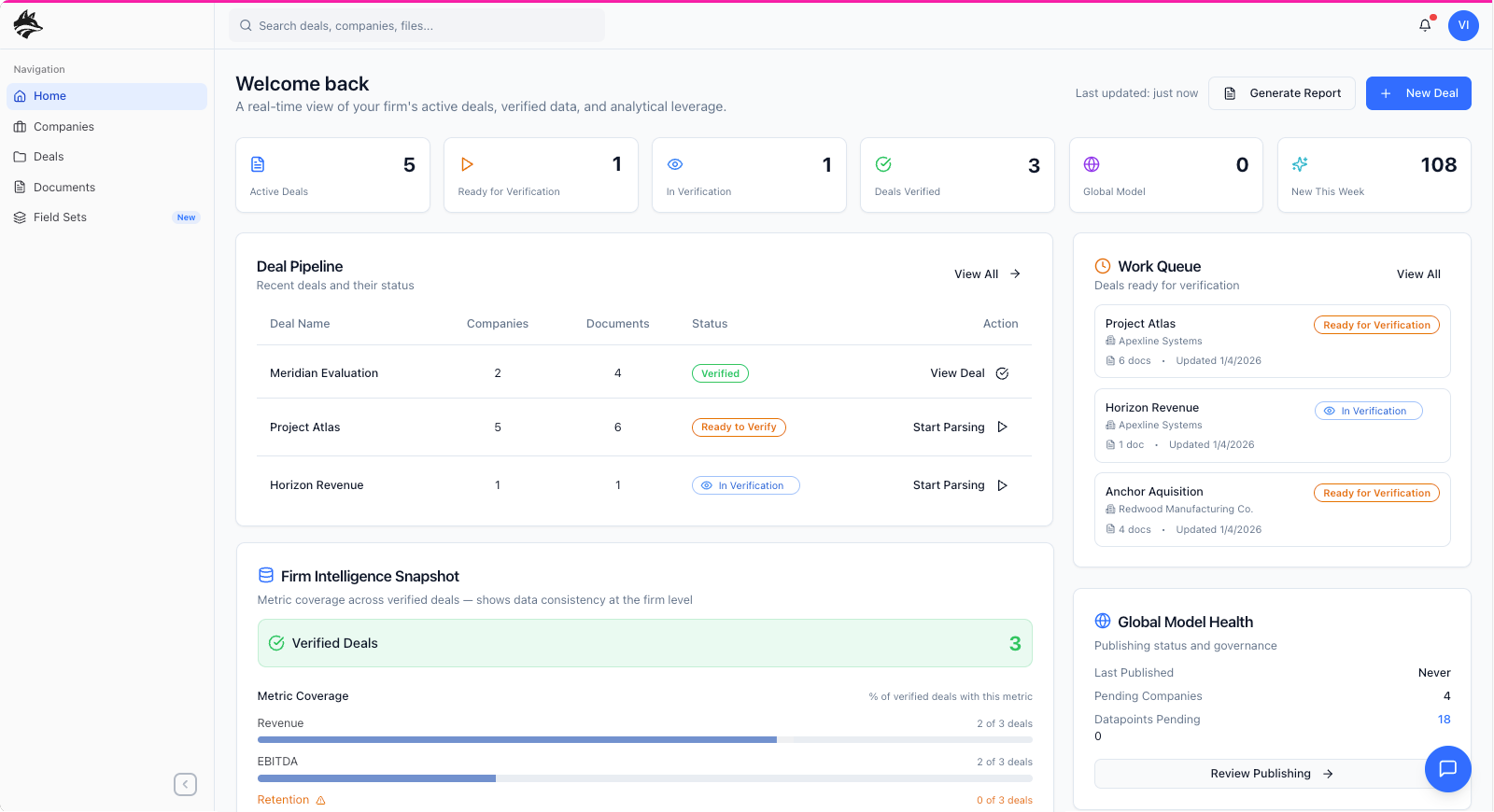
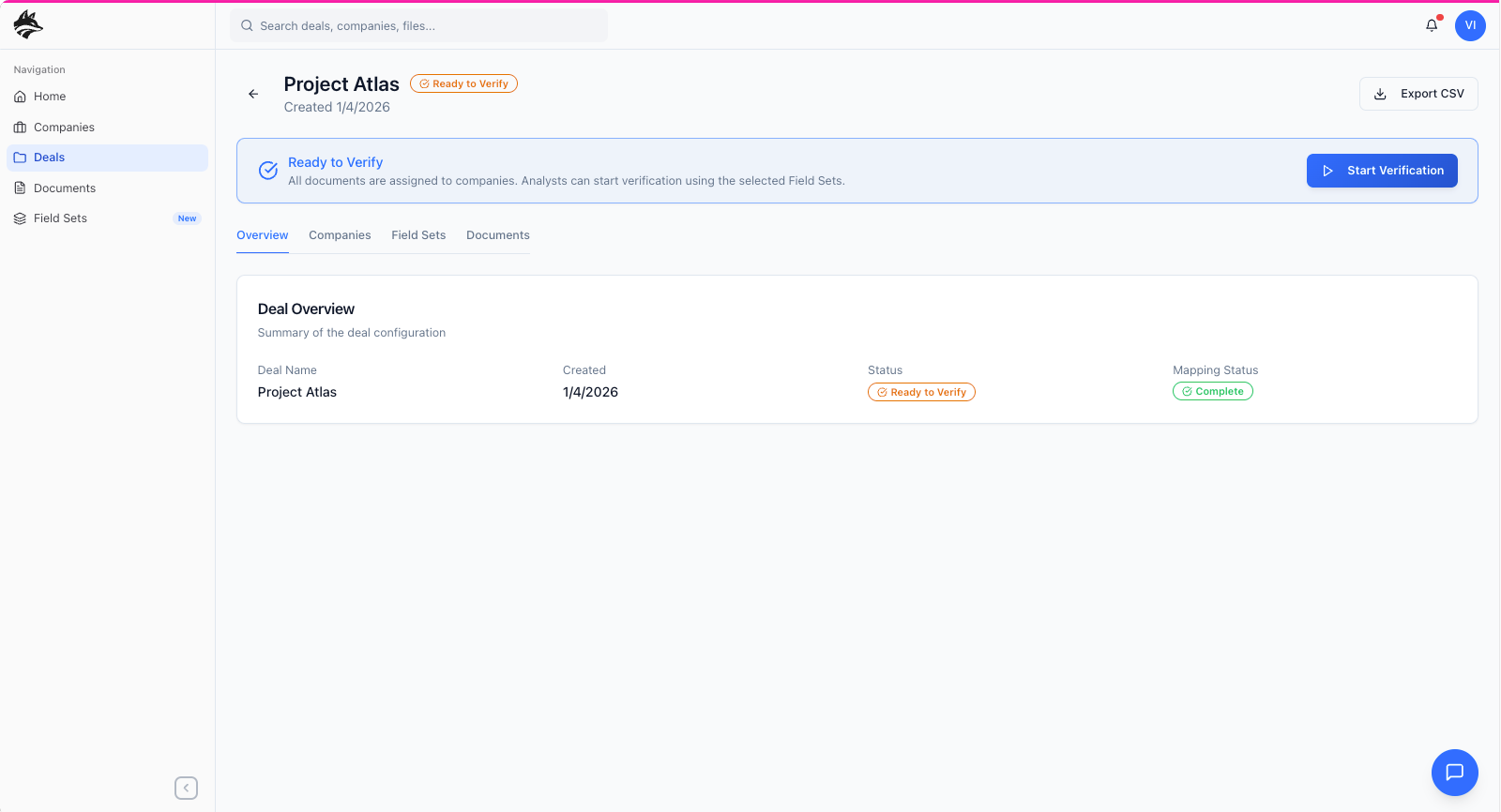
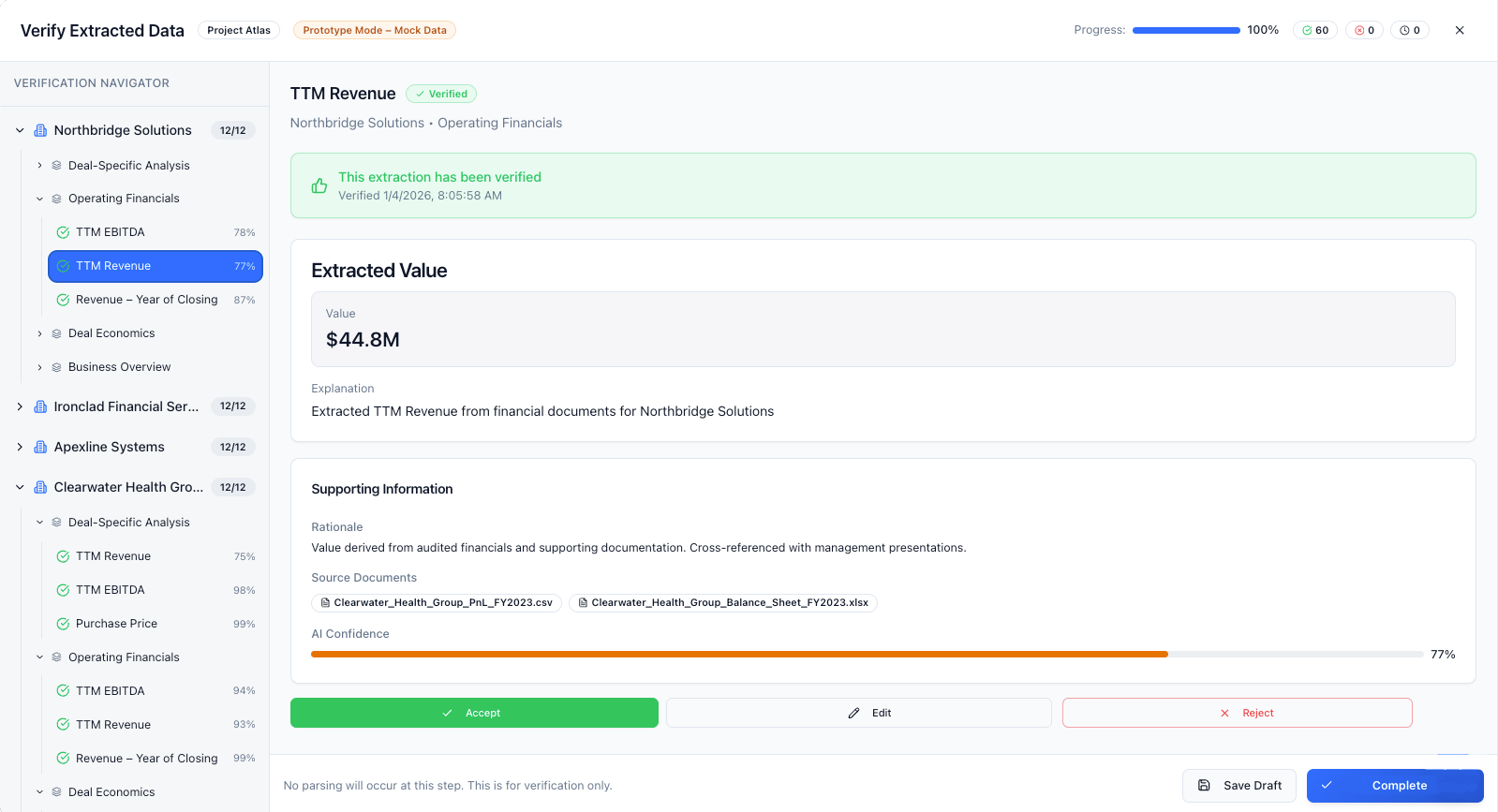
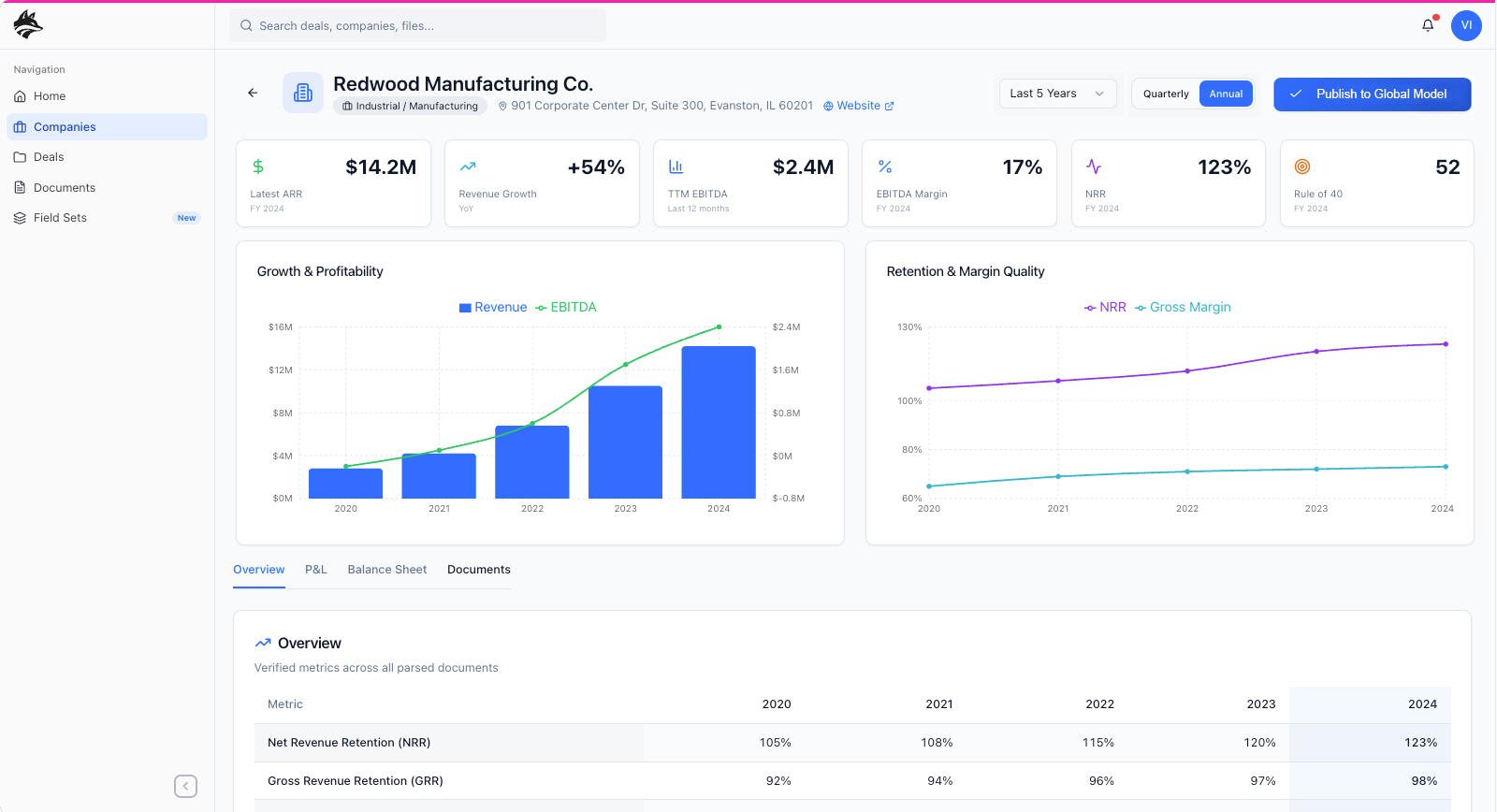
The secondary workflow centers on analyst verification, where extracted data is reviewed, validated, and promoted into the system’s canonical model. Analysts enter the product through the dashboard, where a prioritized work queue surfaces the companies and deals requiring verification, immediately directing them to the relevant company detail view. From there, analysts systematically review each extracted output against source documents, resolving ambiguities, correcting edge cases, and confirming accuracy before publishing the results to the global model. This human-in-the-loop step is intentionally separated from extraction to preserve speed upstream while ensuring trust downstream, allowing DataFox to balance AI-driven scale with analyst-grade confidence.
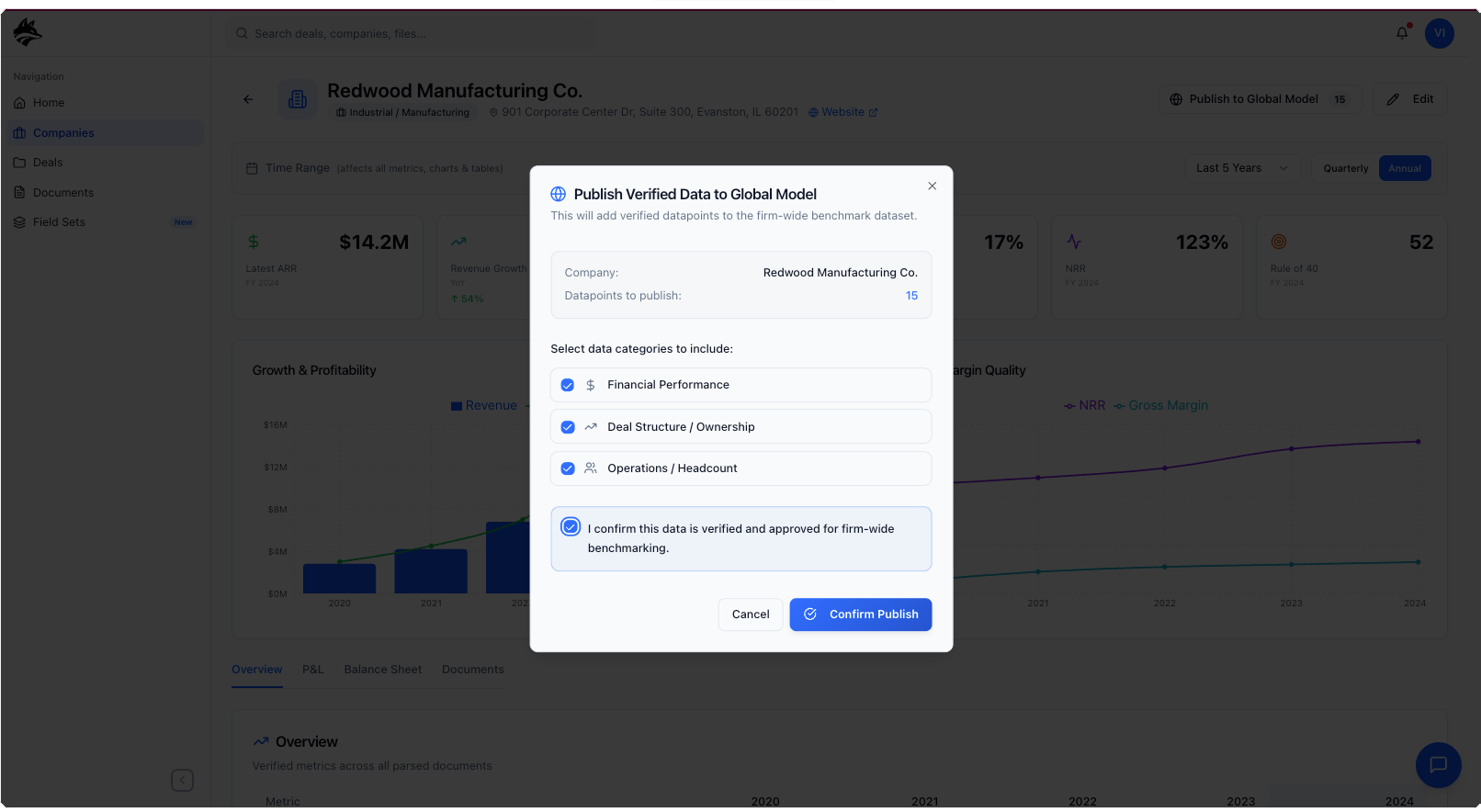
secondary workflow deep dive: publishing to the global model
The final publication step is where analyst verification compounds into long-term product value. Once validated, outputs are published to the global model, transitioning them from deal-specific findings into reusable intelligence that strengthens future extractions. Each verified data point improves the system’s understanding of document patterns, table structures, and field-level nuances across industries, creating a feedback loop where accuracy increases with every completed deal. By tying publication to human-verified outputs rather than raw extraction, DataFox ensures the global model learns from high-confidence signals, turning day-to-day analyst work into a continuous improvement flywheel for the entire platform.
vulpes, the fox in the data room
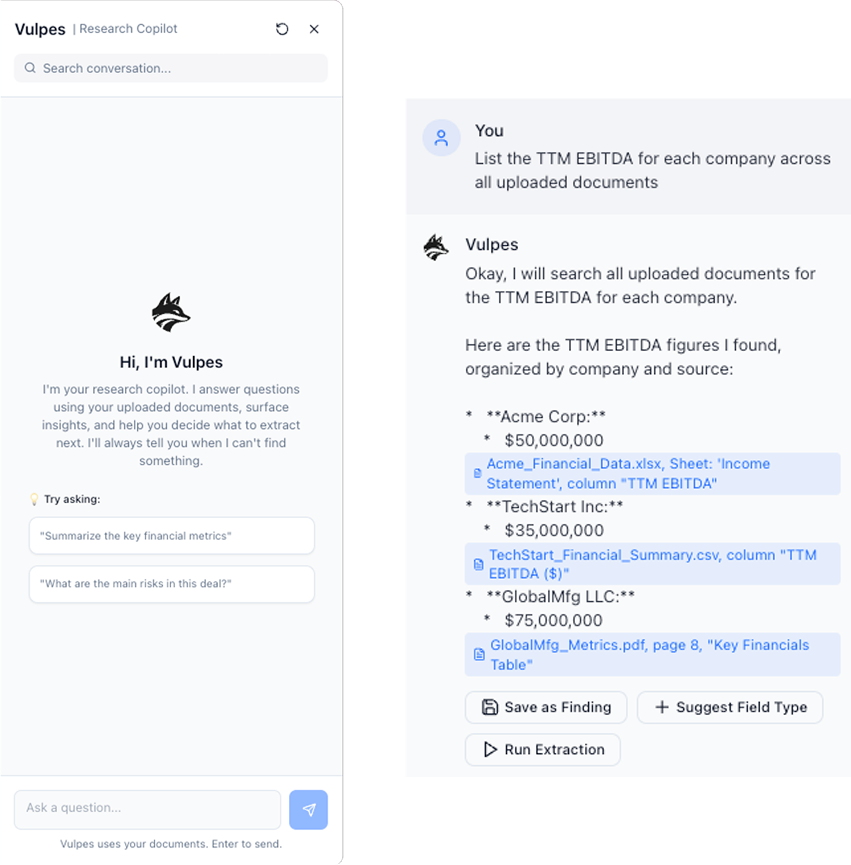
DataFox includes Vulpes, a task-based AI chat agent designed for exploration, synthesis, and ad-hoc analysis alongside structured extraction. Living in a persistent sidebar, Vulpes allows users to query deal materials contextually without disrupting their workflow. Unlike the extraction pipeline, which produces canonical data, Vulpes operates strictly as a retrieval layer—supporting questions, validation, and real-time exploration without writing back into the system. Designing and QA’ing this experience required hands-on iteration across PDFs, CSVs, Excel models, and PowerPoint decks to ensure accurate structural understanding. Through targeted prompt and retrieval refinements guided by GPT, I resolved early issues around tabular comprehension and document scoping, resulting in a more holistic, deal-aware assistant that reliably searches across all relevant materials by default.
what was built, and how far it went
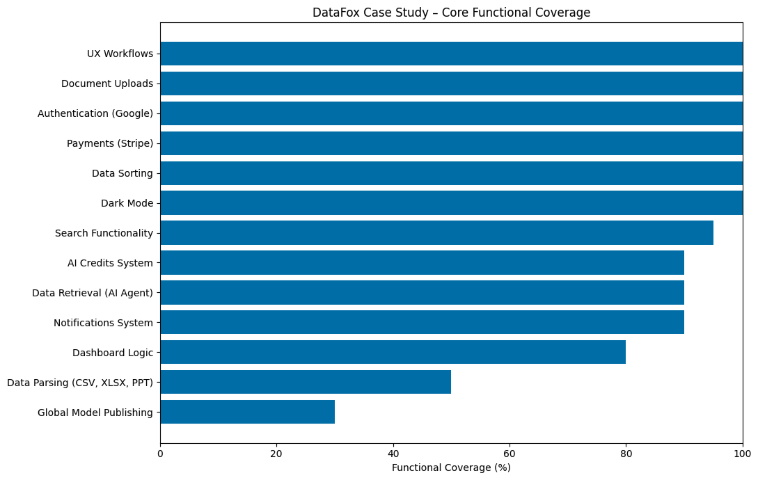
The chart above reflects the functional depth reached during the DataFox case study. All primary UX workflows and platform foundations were fully shipped, with high completion across AI retrieval, usage controls, and system logic. More infrastructure-heavy capabilities, including deep data parsing and global model publishing, were intentionally scoped to partial implementation to prioritize validating the product experience and core workflows.
where ai shines-and where it doesn't
reflection

DataFox ultimately lives somewhere between a case study, a prototype, and a half-built product—and that’s intentional. The core workflows and AI patterns are far enough along that the product could reasonably be handed off to an engineer for cleanup, QA, and production hardening, rather than endlessly refined in isolation. Building it this way let me feel like a product designer again, focused on workflows, ownership, and decision-making instead of component padding and layout minutiae. The product itself can be explored at app.datafox.com, with the supporting context and positioning available at datafox.com, and I plan to continue polishing the experience with the same mindset moving forward.